

TrueFoundry AI Gateway
Connect, observe & control LLMs, MCPs, Guardrails & Prompts
2.1K followers
Connect, observe & control LLMs, MCPs, Guardrails & Prompts
2.1K followers
TrueFoundry’s AI Gateway is the production-ready, control plane to experiment with, monitor and govern your agents. Experiment with connecting all agent components together (Models, MCP, Guardrails, Prompts & Agents) in the playground. Maintain complete visibility over responses with traces and health metrics. Govern by setting up rules/limits on request volumes, cost, response content (Guardrails) and more. Being used in production for 1000s of agents by multiple F100 companies!
Interactive


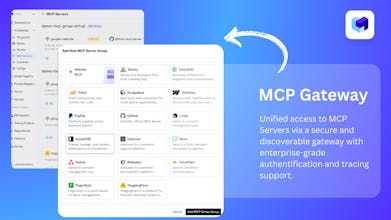
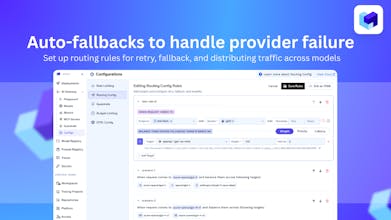

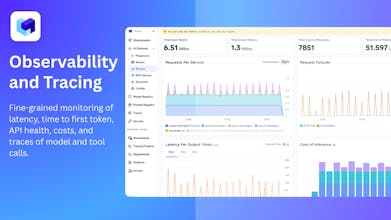

Free Options
Launch Team / Built With



Trace-AI
Kaily
This sounds so interesting. Wondering how it connects to/works with final deployed Copilots. Does it let you design workflows for the Copilot in addition to managing the MCP connections and base LLM?
Demo looks so good! This product is kind of complicated one for me. Demo helped me understand a little bit. I doesn't look like a marketer's tool, though.
I've been testing this for a while, and the observability layer is revolutionary on its own.
Having model latency breakdowns, token usage insights, agent traces, and failure cases all in a single interface saves a huge amount of time when debugging. This is exactly the kind of tooling that pushes LLM applications toward true, mature engineering systems.
🚀 Congrats on the launch! Love how TrueFoundry AI Gateway simplifies multi-model access, centralizes keys, and adds real observability + guardrails. Feels like the missing layer for taking AI apps from prototype to production. Great work!
Looks so cool, can’t wait to test this.
We’ve been testing the TrueFoundry AI Gateway for a few weeks, and it genuinely solved one of our biggest headaches — managing multiple LLM providers and internal models without drowning in glue code. The observability layer alone is worth it; being able to trace prompts, responses, latency, and failures in one place has saved us hours of debugging.
If you’re running production AI workloads or multiple teams rely on LLMs, this is a game-changer. If you’re just experimenting, it might be overkill — but for scaling, governance, and reliability, it’s one of the cleanest solutions we’ve tried.